BEPRO Dev Team
Improving our Football Tracking Data Collection Process
How using MLOps is making a difference at BEPRO

Are you tired of manually managing datasets and trying to keep track of which one you used for a particular experiment?
Or maybe you trained your production model several years ago and are afraid of touching it now, even though the data it is dealing with now might be different?
Perhaps you don’t care about any of that, and just want to improve your model’s metrics, but after trying all the architecture and hyperparameter combinations still ended up short?
Quite surprisingly, in all of these scenarios, you might benefit from “adopting MLOps”.
Here we’ll describe some steps which we took in this direction, hoping that these might be useful or at least interesting.
What’s MLOps?
Before we proceed, we must first agree on what exactly MLOps is. Let’s consult some big companies first.
MLOps is an ML engineering culture and practice that aims at unifying ML system development (Dev) and ML system operation (Ops).
Hmm, this was not particularly enlightening.
A shorthand for machine learning operations, MLOps is a set of best practices for businesses to run AI successfully.
Now that’s more interesting, but still fairly vague.
Azure (Microsoft) documentation:
MLOps — machine learning operations, or DevOps for machine learning — enables data science and IT teams to collaborate and increase the pace of model development and deployment via monitoring, validation, and governance of machine learning models.
I guess that’s as detailed as it gets.
If we try to summarise these definitions, MLOps is a set of practices that help in AI model development.
But it we ask Andrew Ng — the answer is going to be somewhat different. It can be roughly rephrased as — if we seek to improve the performance of the system, perhaps we should focus less on the models, and more on the data, and in the linked video he provides some examples of the motivation for this.
These two perspectives do not directly contradict, yet the difference in what is being emphasised tells us an important thing — MLOps is interesting for different reasons, and it depends on whom are you “selling it” to, a business owner or an engineer, an enterprise company or a startup.
Perhaps another way to put it would be analysing the main potential for improvement in an ML service — better metrics? less manual work for each model update iteration? more stable deployments? less regressions? and then systematically addressing it with some concrete measures.
This would mean that “adopting MLOps” is somewhat of an umbrella term, which might mean different things for different companies at different stages, so to be more specific we’ll focus on particular aspects that were important to us at BEPRO.
MLOps at BEPRO
For us, it seemed that the best starting point for employing MLOps practices would be for automating dataset collection procedures and to make it happen at regular intervals.
Previously, a dataset would be collected manually according to certain criteria (pitch, teams, weather conditions, etc), and would be handed over to a third-party company to do the annotation. But during the lifecycle of the product, a lot of annotated data is already being generated, and not using it would be wasteful.
Besides, immediately incorporating the acquired data would mean less potential for the models to become outdated (once we start operating in new pitches, with new teams, more diverse weather conditions, etc) and opportunities for collecting more data in a targeted manner (samples where the current models are not accurate enough).
Finally, if the data collection / preparation process is not performed frequently, it often becomes “sacred knowledge”, that is either lost, or known only to select few engineers, making it harder to check new hypothesis (sometimes to the point where such tasks are completely avoided).
Not only would “adopting MLOps” make the data collection process more transparent and systematic, it would also allow us to increase the dataset size very significantly (orders of magnitude) with regards to the number of samples and the number of matches, which is expected to noticeably improve the model’s metrics.
Initial Research
In order to avoid reinventing the wheel, we used off-the-shelf open-source tools that help with dataset management and automation.
Dataset Management
We work with (versioned) datasets where each version contains millions of files that come to hundreds of gigabytes, so speed and storage efficiency are crucial. To manage these we decided to use DVC, since it doesn’t get in your way and has a git-like interface that makes it easier to get a hang of (although initially it still might take some effort to get comfortable with).
We mostly care about the following points:
Easily uploading / downloading the dataset to our cloud storage of choice using any machine (helps to scale training / hyperparameter search)
Avoiding using extra storage / transfer bandwidth if different datasets or dataset versions overlap in terms of samples
Making sure that the version of the data would be exactly equivalent between machines without any manual steps (less room for human error)
Point one should probably be taken for granted for a dataset management system, so we’ll focus on point two here (and doing it properly involves the third point).
Assume you have two datasets (or versions of the same dataset) A and B, which contain samples {1, 2, 3, 4, 5} and {2, 3, 4, 5, 6}, respectively.
Naive solutions would store them separately, requiring storage for 10 samples, but with DVC you’ll store only six samples and some extra data to define which dataset has which samples (which would typically be negligible as long as you are working with relatively large binary samples).
If we already have dataset A locally and want to download dataset B — you’ll need to download only a single sample instead of five.
This example might look trivial, but having a system that can handle it efficiently makes a very significant impact on the storage and bandwidth requirements as well as speed of operations, which become critical as soon as you start regularly creating new versions of datasets in an automated manner, uploading them to a cloud and downloading to agent machines for training or other purposes.
Also, in our case it might be possible to have datasets for different tasks (object detection, player shirt number recognition, camera position estimation, etc) that share the images, but have separate labels without increasing cloud storage usage. Of course it is also possible to achieve manually, but this would require coordination between people that maintain different datasets, whereas in this case they might push/pull to storage their data independently, and it will be reused as much as possible under the hood.
Even with this you still have to take special care when collecting data to make sure that the cache would be reused as much as possible without sacrificing the model performance — more on this later.
Automation and Integration
Since we use GitHub as a repository storage, it was a natural choice to use GitHub Actions to automate some jobs.
Many of the jobs would be relatively long-running and require a GPU, so we needed to use some custom agents instead of the ones provided by GitHub.
To do that, we used CML, which also allows to send reports as comments to commits and PRs.
Apart from the typical software development usages (run lint and tests for each commit / PR), we used several manually triggered jobs:
Make a report about samples, which are available for inclusion into the dataset (a nice markdown table that allows us to compare the dataset to be exported with a previous one to determine if it is worth retraining the model)
Actual dataset export, with the possibility to select the branch of the repo with the code and configuration to use and also to override some of the export settings (size of the dataset, etc)
It is possible to run the export automatically according to the schedule, but it didn’t make sense to perform it more often than once a month, so there was not much to gain in terms of saved time. The same goes for training the model with the updated dataset — it is easy to do in principle, but automating it would reduce the amount of control that we have over the process and wouldn’t free up much time.
A convenient aspect of the current integration is that once the dataset export is complete, the data is automatically uploaded to the cloud storage via DVC, and the identifiers for the uploaded data are posted as comments under the commit that was used to perform the export, along with the configuration file content that determines export settings. This ensures that it is easy to find a particular version of the dataset and it wouldn’t be lost, unlike in a scenario where datasets are managed manually.
This way the developers that don’t work with this system directly might use the exported datasets in their projects, without having to run any data collection / cleanup themselves (allowing us to have separate specialists that focus on data cleanup and on training the models).
Pilot Project
Here, we’ll be using multiple object tracking task as an example. In this case, an image is an input to the model, and expected output is a set of bounding boxes, each accompanied with an object class (player, ball, etc) and an embedding vector, which will be used during the re-identification stage.
Obtaining the Labels
During the lifecycle of our product predictions from the models are being reviewed by human experts, and the corrected results (bounding boxes, class and player identity labels) are saved in a database, providing a source of data that we can consider to be ground truth.
Here’s an example of the bounding boxes with corresponding player IDs overlaid on top of the image:

In an ideal world we would’ve used it as is, but in our case we have to go through some cleaning first.
An example of a case that needs extra attention:
When a human expert corrects missing boxes, the boxes are placed only in frames where the velocity vector of the player changes, and their positions in the remaining frames are expected to be interpolated
When a player crosses the sideline to leave the pitch — they are not included in the annotation until they have returned to the pitch
When the two conditions above are combined, “ghost” trajectory chunks will be generated (a slow moving box from the point of exit to the point of entry onto the pitch), and unless some data cleaning is performed — such artifacts will negatively impact the trained model
Another potential problem is synchronisation between video frames and labels, which might be slightly inaccurate sometimes. It’s not a problem for the users of the product, but during the model training even a single-frame offset has a negative impact, so ideally it should be compensated.
We tackle both problems by comparing the labels with outputs from the best available model, and then estimate:
Optimal offset for label and frame synchronisation
Alignment between corrected labels and predictions (loss, IoU or any other meaningful measure could be used)
Then, using this information, we can filter the samples to include only ones with reasonable agreement between labels and model output.
Sample Selection
After quick back-of-the-envelope calculations it became obvious that it wouldn’t be possible to include all the samples that we have in our dataset due to the projected size. Since we’re working with video-based data, consecutive samples are strongly correlated, which makes including all of them even less meaningful. Finally, due to the nature of the process that we use to obtain the ground-truth labels, some of these are less accurate than the others, making their inclusion undesirable.
Keeping this in mind, we have ended up with the following strategy:
For a given frame step parameter and the range of relevant frames, prepare a list of frame indices for export candidates
Drop frame indices for samples where the number of players in the label doesn’t match expectations (mostly to exclude non-game situations)
Measure the agreement between labels for each of these with output of the current best model, drop indices for frames with extreme disagreement
These points were mostly related to the selection of samples from a video, but selection can also be applied to the set of the videos as well. Different strategies might be employed, and while it is not clear which one is the best, we have decided to go for the data diversity maximisation within a fixed sample budget. It can be roughly expressed as: “when facing a choice to include either sample A or sample B into the dataset, include the one which is more ‘novel’ (has less similar samples in the dataset already), repeat N times”.
How can one determine if the videos are “similar” or not? In our case, each video is assigned a set of categorical properties (pitch, home team, away team, etc), and a combination of these properties defines a “group”. For each group we include up to a limited number of videos, one of which goes to the validation set, and the rest — to the training one. Such a procedure ensures that there’s no extreme imbalance between sizes of groups and avoids too much storage being used for well-represented groups.
Caching
Even with such measures, downloading (and pre-processing) samples from scratch each time the export is performed would take an unacceptable amount of time, forcing us to employ caching for each of the steps (and strategies for cache invalidation). Having a caching mechanism alone is not enough though, since one must also make sure to select and store samples in a cache-friendly way.
This means that, for instance, if at time t1 we select matches M1, at time t2 (when more data is available), M2 should be a superset of M1 (include all matches that we had previously + some new ones), the selection criteria from (pick N matches from G) shouldn’t change.
As an example, let’s compare two policies for choosing a subset of samples from a group — using the N newest ones or N oldest ones available. If we were to use the newest ones — such a subset might change after each re-export, making some samples in the cache unused and requiring the downloading of new samples. But if we use the oldest samples such issues would not arise, making caching more effective.
After implementing all of this, regular exporting would only download and pre-process the samples incrementally, avoiding most of the time expense. Besides, instead of needing sum(each dataset version size) we’ll need only max(dataset size) (assuming that datasets are not disjointed in samples).
Downloading the Samples
The naive approach would be to download the video file and then extract the frames from it using OpenCV or another tool, but depending on the number of frames that would be extracted from the video this might be inefficient (assuming you need only one frame from a three hour video as an extreme example).
ffmpeg to the rescue! With it, we can extract a specific frame from a remote video without downloading the whole thing. Initially we had concerns about the accuracy of frame selection, since “fast seeking” with ffmpeg is possible only via specifying the time offset, and not the frame index. Of course, by knowing the frame rate of the video you should be able to infer the time offset for a particular frame, but by doing this you have to assume that the time interval between frames is very consistent throughout the whole video, and that the seeking functionality is precise enough. Fortunately, such an approach was accurate enough for our use case, so we stuck with this approach.
The only issue with that was working with m3u8 playlists instead of mp4 files — ffmpeg was not able to perform an accurate fast seek to the exact timestamp, which resulted in a lot of frames with a severe mismatch between image and labels. We’ve resolved it in a relatively straightforward manner, by first performing a fast seek to a timecode a few seconds before the frame of interest, and then doing an “accurate” or “slow” seek to the exact timecode of the frame we need — it worked well enough for our use case.
Finally, in order to speed up the overall process, frames are acquired using this process in parallel, using a pre-determined number of processes, which depends on network, CPU and input data.
Benchmarking
So far we’ve mostly been referring to a scenario where the acquired data is used for training the model. But obviously this is not the only potential application, and it could also be used for end-to-end benchmarking of the system.
In our case it meant working with the videos instead of images and measuring the metrics which are important for the product (and might be harder to measure when one or all of the models are trained in isolation). Using the sample groups that were established during the data collection, we could automatically generate (or update) a set of inputs and expected outputs for the benchmarks (quality and performance related).
One obvious issue with such a “dynamic” benchmark is comparing the results of models which were evaluated on different “versions” of the benchmark. We address it in following fashion:
Once the sample (video) is included into the benchmark — it could not be excluded, only new samples could be added (unless we want to invalidate it completely)
Metrics are measured and stored on a per-sample basis (allowing to “update” previous results incrementally, rather than recalculating completely)
Once new samples are included — old models are simply evaluated on these new samples, and the aggregate benchmark results are updated
Such an approach allows us to avoid expensive reruns and is relatively easy to accomplish.
Results
One might wonder if going through all these steps was worth it. In our case it was definitely the case:
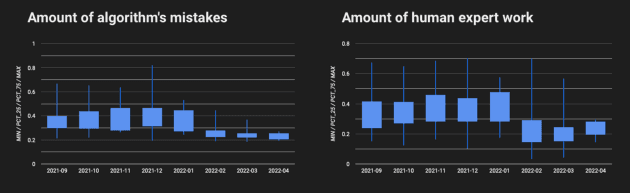
Using the data, which was collected using the steps described above, we have been able to achieve > 40% error reduction in multiple object tracking task (different types of errors are weighted differently, which is a topic for another article🙂)
As a result of that, the amount of human expert work was decreased > 25%, which reduces the net cost of providing the service significantly
Regularly rerunning the dataset collection pipeline doesn’t take more than few minutes of developers’ time, likewise with using a new version of the dataset to retrain the model (even though these processes might take significant time, developers can still focus on other tasks in the meantime)
Next Steps
We are still in the process of “adopting MLOps” at BEPRO, so there are several obvious next steps, some of which are:
Expanding to other tasks
Evaluating different sample weighting schemes
Pseudo-labelling the samples for which we don’t have human expert annotations (a lot more samples with different conditions become available with such approach)
It is also interesting to evaluate the long term return of continuous dataset collection and model retraining. So far we have been able to get improvements by incorporating more data over time, but these are expected to be diminishing, and over time most likely would be limited by the model capacity/architecture.